Tiskane izdaje
Tiskane izdaje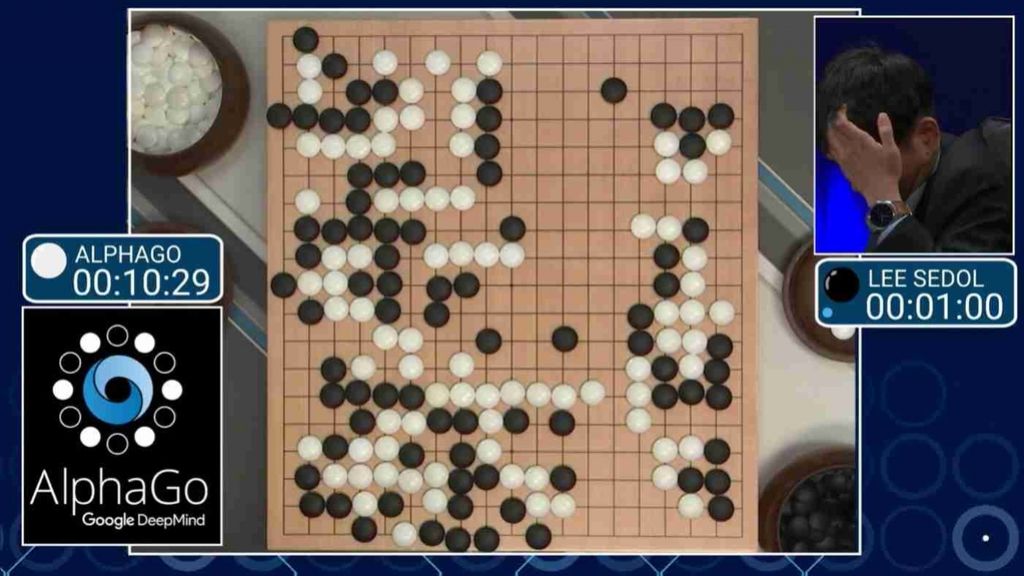
»Področje umetne inteligence je v zadnjih petih letih skokovito napredovalo, vendar nekateri problemi še niso rešeni,« pravi Marko Grobelnik, raziskovalec v laboratoriju za umetno inteligenco na IJS in digitalni glasnik Slovenije, ki redno sodeluje z vrsto akademskih institucij po svetu, med drugim z Univerzo Stanford in Univerzitetnim kolidžem v Londonu (UCL).
Sogovornik, strokovnjak za različne vidike umetne inteligence, za analizo velikih količin tekstovnih podatkov, strojno učenje, analizo omrežij, vizualizacijo podatkov in kombinatorično optimizacijo, je med drugim soustanovitelj podjetja Cycorp Europe ter direktor in ustanovitelj podjetja Quintelligence – inteligentno upravljanje z znanjem, sodeluje pa tudi z nekaterimi pomembnimi evropskimi in ameriškimi podjetji, kot so British Telecom, Microsoft Research, IBM Watson, New York Times in Bloomberg. Septembra ga je slovenska vlada imenovala za nacionalnega glasnika digitalne tehnologije za štiriletno mandatno obdobje.
Pred letom dni je računalniški program AlphaGo premagal svetovnega prvaka v igri go, kar velja za enega največjih dosežkov umetne inteligence. Zakaj je v zadnjih letih strojno učenje tako hitro napredovalo?
Medtem ko se je umetna inteligenca v preteklih dveh desetletjih razvijala bolj v ozadju, v senci spletnih in mobilnih tehnologij kot podpora za obvladovanje masivnih podatkov, ki so nastajali kot posledica hitro razvijajočih se dejavnosti v povezavi z internetom, je v zadnjih petih letih doživela res velik skok v razvoju. Ta presenetljivi napredek je spodbudil preporod v strojnem učenju z vrsto metod, ki jih imenujemo globoko učenje. Te metode pravzaprav konceptualno niso drugačne, kot so bile v 90. letih, vendar so bili takrat računalniki bistveno manj zmogljivi in tudi podatkov ni bilo toliko na razpolago, zdaj pa so računalniki veliko bolj zmogljivi, paralelni in količine podatkov so ogromne.
Ko sta bila izpolnjena ta dva pogoja, so raziskovalci strojnega učenja začeli oživljati tehnike, imenovane nevronske mreže, ki v osnovi niso zelo zapleten mehanizem, čeprav se morda tako zdi. Pravzaprav bi jih lahko izdelal že srednješolec z znanjem programiranja, vsaj v bolj preprosti, osnovni obliki. Ampak če ta mehanizem uporabimo na izjemno zmogljivih računalnikih z masivnimi podatki, lahko kar naenkrat rešimo nekaj pomembnih problemov, ki prej niso bili rešljivi.
Precejšen napredek pomeni razvoj računalniškega vida.
Tako je. Računalniki zdaj »vidijo«, kar je zelo pomembno za vrsto aplikacij. Nadalje, tehnike globokih nevronskih mrež so močno vplivale na razvoj prepoznave govora, na strojno prevajanje in obdelavo različnih zelo šumnih podatkov, kot so slike, zvok in jezik. Te rezultate so hitro uporabila velika podjetja, Google, Microsoft in Facebook, ter jih vgradila v svoje izdelke. Primeri izdelkov, ki se opirajo na te tehnologije in jih vsakodnevno uporabljamo, so google photos, google translate in bing translate ter pametni agenti, kot sta Amazonov echo in Applov siri. Ta tehnologija je prav tako bistveno izboljšala Googlov iskalnik, hitro pa se razvijajo tudi avtonomna vozila.
Pri tem bi rad posebej poudaril, da so velika podjetja, se pravi Microsoft, Google in Facebook, ravnala zelo prijazno in dala tako rekoč vse pomembne programske pakete s področja globokega učenja v javno uporabo, tako da jih lahko vsak uporablja. Danes lahko študentje, ki pripravljajo diplomo, magisterij ali doktorat, uporabijo pakete teh podjetij, si jih naložijo na računalnik in kar naenkrat rešujejo probleme, ki jih še pred desetimi leti nihče ni mogel reševati.
Kateri problemi pa so ostali nerešeni in so trenutno največji izziv za raziskovalce umetne inteligence?
Tehnike, ki sem jih omenil, so sicer zelo zmogljive, vendar so za obvladovanje zapletenih struktur, kot je razumevanje besedila, prešibke – podatke opazujejo zgolj na površju, ne gredo zares v globino. Na predavanjih ta problem pogosto ponazorim s slavnim Wittgensteinovim stavkom »Meje mojega jezika so meje mojega sveta«. Ta stavek pri umetni inteligenci kar drži. Najprej se lahko vprašamo, kakšen jezik uporablja računalnik – od tega je odvisno, kako se lahko izraža in koliko zna povedati. Čim močnejši jezik uporabljamo, več lahko povemo.
Vprašanje jezika, v katerem računalnik razmišlja in se izraža, je sicer kar dobro raziskano. Precej manj raziskano pa je vprašanje »sveta«, kot ga vidi računalnik. Razumevanje »sveta« oziroma konteksta je namreč v današnjih sistemih umetne inteligence zelo omejeno in v tem smislu so omejene tudi rešitve, ki jih lahko pričakujemo. Realni svet, v katerem živimo, je bistveno bolj zapleten in ga računalnik vidi samo po koščkih, ki pa nikakor niso povezani. Torej, če se vrnem na Wittgensteinov stavek, lahko rečemo, da si prizadevamo računalniku razširiti svet zato, da bi lahko v tem širšem svetu iskal rešitve, ustrezneje povezoval stvari in reševal zahtevnejše probleme.
Ali tovrstne tehnike uporabljate tudi pri delu za velike medijske hiše, kot sta New York Times in Bloomberg?
Naše sodelovanje z New York Timesom se je začelo leta 2007, ko sva imela s kolegom Blažem Fortuno predavanje na neki konferenci v San Joseju v Kaliforniji. K nama je prišla skupina treh sodelavcev tega dnevnika , ki so poslušali najin nastop, povedali so, da uporabljajo naše programe, ter vprašali, ali bi hotela sodelovati z njimi. Dejali so tudi, da morajo do naslednjega dne sestaviti neko poročilo, in prosili, ali bi jim lahko še tisti večer nekaj popravila v programski opremi. To sva naredila in že čez en mesec smo imeli z njimi pogodbo.
Kmalu smo začeli redno obiskovati New York Times, kjer smo dobili dostop do podatkov in razvili programsko opremo za različne storitve. Kasneje je eden od sodelavcev z New York Timesa odšel k Bloombergu in tako se je sodelovanje nadaljevalo tudi tam. Začeli smo z manjšimi problemi, ki so z leti zrasli v precej večje, zahtevne projekte. Del teh aktivnosti je povezan z mediji, del pa z Bloombergovimi finančnimi in poslovnimi produkti.
Se je vaše delo, povezano z mediji, večinoma nanašalo na oglaševanje?
Večina teh projektov je bila povezana z oglaševanjem in razumevanjem uporabnikov. Zanimalo jih ni zgolj, kako pridobiti čim več oglasov, temveč predvsem, kako obstoječe oglase čim bolj natančno privesti do ciljnega občinstva. Torej, eno so oglasi, ki so preprosto razpršeni po različnih vsebinah – ti so najcenejši. Drugi tip so oglasi, za katere so oglaševalci pripravljeni veliko plačati, vendar samo, če jih vidi izbrano ciljno občinstvo, in ti ciljni bralci so natančno opredeljeni, na primer, biti morajo odločevalci, bogati, zaposleni v ugledni finančni ustanovi, živeti v izbranih geografskih okoljih in podobno.
Velike medijske hiše imajo dnevno po več milijonov obiskovalcev, o katerih se v resnici veliko ve, ne samo iz internih podatkov medijskih hiš – če dokupijo podatke od raznih dobaviteljev osebnih podatkov in jih združijo s svojimi, potem o svojih uporabnikih vedo zelo veliko. Vidi se njihova spletna aktivnost, kaj berejo in kdaj, od kod so, komu so podobni, s kom se družijo, katere izdelke si ogledujejo.
Se ukvarjate tudi z analizo medijskih vsebin?
V ta namen smo na Institutu Jožef Stefan sprva predvsem v raziskovalne namene razvili sistem event registry, dostopen na http://eventregistry.org/, katerega cilj je spremljati svetovne medije v realnem času. Začelo se je kot povsem akademski projekt, ki naj bi pokazal, ali znamo opazovati, razumeti in napovedovati globalno družbeno dinamiko na podlagi medijskih vsebin, pri čemer smo na inštitutu že imeli razvite jezikovne tehnologije, ki omogočajo hkratno obdelavo besedil v približno sto jezikih. Bodisi da so besedila napisana v kitajščini, slovenščini ali pa v nekem jeziku, za katerega komaj vemo, da obstaja, bo sistem to zaznal in iz teh besedil povzel ključne vsebine, jih povezal in ustvaril dogodke. Tako s pomočjo tega sistema sveta ne vidimo skozi množico člankov, ampak kot množico dogodkov, ki se povezujejo v daljše zgodbe.
Event registry zbere približno pol milijona člankov na dan, iz njih identificira od 5 do 10 tisoč dogodkov in nato te dogodke povezuje v zgodbe, kar omogoča, da gremo zelo daleč v informacijski prostor vsega svetovnega dogajanja. Sistem deluje enako dobro, če vprašamo, kaj se dogaja v Chicagu, v Murski Soboti ali pa v neki kitajski vasi. Opazujemo lahko različne pojave, denimo, kako je informacijski prostor v neki državi manipuliran, vidi se, kako pomembne teme med seboj tekmujejo, kako se eno temo izrinja in tudi, kako se nekatere teme iz političnih ali komercialnih razlogov ustvarjajo in načrtujejo.
Kaj kot nacionalni glasnik digitalne tehnologije menite o odprtem pismu ustanovitelja svetovnega spleta Tima Bernersa-Leeja, ki ga je objavil pred dobrim mesecem dni in s svojimi stališči vzbudil veliko pozornost mednarodne strokovne javnosti, saj opozarja na tri ključne probleme, ki jih je »treba rešiti, da bi se svetovni splet razvijal kot orodje, ki služi vsemu človeštvu«?
Na kratko: vsi trije problemi obstajajo, so zelo resni in vplivajo na življenje posameznika, skupin, držav in celega sveta. Problem se lahko rešuje delno, po državah – ni pa nujno, da je to ustrezna rešitev, ker so problemi globalni, državne meje in pravni sistemi pa so lokalni. Če bi se reševanja teh problemov lotili z enostavnimi rezi, bi to pomenilo grožnjo za »nevtralnost in odprtost interneta«, ki si jo vsi želimo. Znano je, da nekatere države ukinjajo dostop do določenih virov na internetu.
Če pokomentiram še vsak problem posebej. Prvič, Berners-Lee opozarja: »Izgubili smo nadzor nad osebnimi podatki.« Problem izgube zasebnosti je verjetno najbolj kritičen. Preveč je močnih deležnikov, ki niso zainteresirani za ščitenje zasebnosti. V resnici obstaja cela industrija, ki trguje z osebnimi podatki, in načeloma lahko do takih podatkov pride vsak z nekaj denarja. Predvsem so kritične posledice izgube zasebnosti, ki lahko močno vplivajo na življenje posameznikov, kar včasih pomeni tudi izgubo kariere ali v skrajnih primerih celo izgubo življenja.
Drugič, Berners-Lee pravi: »Lažne informacije se po svetovnem spletu vse preveč zlahka širijo.« Ta problem je kritičen, vendar nekoliko lažji od prvega, ker gre za vzpostavitev sistema zaupanja in verodostojnosti informacij. Tu je morda glavna težava v medijih, ki skušajo zaradi medsebojnega tekmovanja objavljati informacije hitro, še preden jih preverijo. Internet pa omogoča bliskovito širjenje podatkov, in ko je enkrat informacija na spletu, jo je težko ustaviti. Tu bi bil primeren ukrep velikih internetnih podjetij, kot sta Google in Facebook, da bi poskrbela za verodostojnost informacij, ki jih razširjajo. Tovrstna podjetja imajo pravzaprav dober razlog, da bi to storila, saj slabe informacije zmanjšujejo kakovost njihovih storitev.
In tretjič: »Politično oglaševanje na spletu bi moralo biti pošteno in jasno.« Ta problem je verjetno najlažje urediti, ima pa tudi največjo težo za življenje večjih skupnosti, kot so države in okolja, kjer se politika odvija. Problem je še posebej izbruhnil med nedavnimi volitvami v ZDA, kjer internetna infrastruktura ni bila pripravljena na moderno politično oglaševanje. Kot se zdi, bodo v podobnih primerih, recimo pri bližnjih volitvah v evropskih državah, zadeve bistveno bolj nadzorovane.
Kakšno je stališče do te problematike v Sloveniji? Obstajajo predlogi za morebitne ukrepe?
Slovenija o teh zadevah razmišlja, podobno kot druge evropske države – trenutno še ni posebnih ukrepov, verjetno pa bodo sprejeti na evropski ravni, kjer bo Slovenija dodala svoje mnenje.
Marko Grobelnik: Umetna inteligenca tiho prodira v naše življenje
Raziskovalec v laboratoriju za umetno inteligenco na Institutu Jožef Stefan in digitalni glasnik Slovenije o novostih v razvoju umetne inteligence.
Objavljeno
05. maj 2017 13.14